
I have created the first version of the “Moodilyzer“, a neural network that analyzes your mood! It is hilariously bad. However, it does something, and that is a starting point for improvement.
I used 13 single-output neural networks as discussed in earlier posts, and I put them behind a django server using mod_wsgi. There are great tutorials on the django/apache piece at djangoproject.com, Digital Ocean, python.org, etc. I really didn’t have to do much outside of the lines there, except uninstall python 2.x, and add this little nugget to wsgi.py, let’s see if I can highlight it sensibly:
import os
import sys
from django.core.wsgi import get_wsgi_application
path = u"/path/to/django/moodilyzer/moodilyzer"
if path not in sys.path:
sys.path.append(path)
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'moodilyzer.settings')Hmm it seems I need a plugin to highlight things. Not big on plugins at the moment, I have been doing just fine with the basic functionality. But anyways here’s the part I added:
if path not in sys.path:
sys.path.append(path)I am sure there is another way to do that. But this one also works.
I also made the rookie mistake of posting stuff to github with my local directory information in it! I quickly fixed it, but it is no doubt visible in the history so I just moved my django stuff. I had it in apache’s html directory, which I’m not supposed to do anyway, so I was going to have to move it eventually.
But anyway, on to the interesting part – the neural network! In order to get this to work I had to reduce the batch size to 1, because otherwise I guess it’s expecting me to submit 55 sentences every time? That makes the training rather slow, so I separated the scripts into training and inference, with the inference embedded in the django application. Inbetween, the model is saved to a file with pickle. I had to separate the SentimentalLTSM class into its own file so both sides could use it. This works really well! Pytorch can load all of the models pretty instantaneously. It only takes on the order of a second to get results.
The results of course are all over the place, and I think there are many reasons for that. A neural network, if I recall correctly from my studies, is nothing more than a hyperplane separator. This means that it is really good at separating groups of things like so:
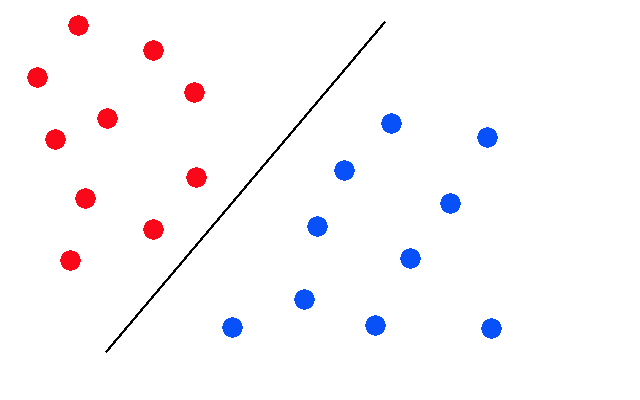
But it is really bad at separating things that look like this:
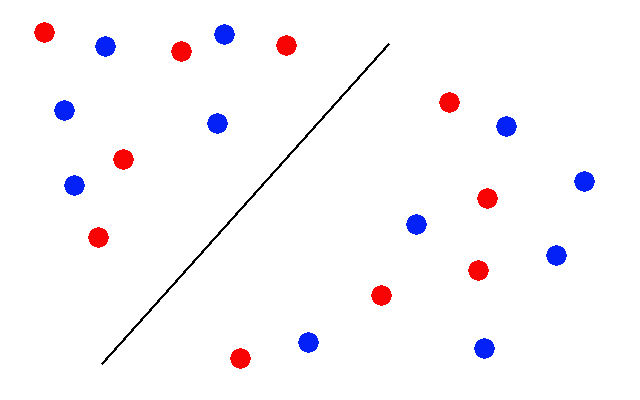
And I think that second situation is what we have created here. Particularly in how the dictionary of words was created. It was created strictly by popularity of words:
# create word-to-int mapping
vocab_to_int={w:i+1 for i,(w,c) in enumerate(sorted_words)}Let’s say we are trying to classify “good” moods vs. “bad” moods. Well the word “good” was assigned a value of 38, and “bad” 382. But then “awesome” is at 740! There’s no number you can pick that divides good words from bad words. And that’s essentially what we’re trying to do.
So in order to fix that, we’d have to find some other way to assign numbers to words – one that somewhat reflected where they were on the spectrum of emotion we’re trying to capture. For example, in the “happy” neural network, we might want to assign 100 to “happy”, and -100 to “sad”. Then we train the output such that positive numbers are happy, negative numbers are sad, and something around 0 is “can’t tell”.
But what about the word “not”? What if the text we’re trying to analyze is “I am not happy”? In that case we’d want to negate the input of the word “happy”, in essence equate “not happy” with “sad”. But in order to do that kind of thing, we have to start parsing sentences, paying attention to parts of speech and so on. Which is something I think we’d want to do anyway, because consider the following sentences:
I am not happy.
When it rains I am not happy, and I don’t know why.
It would be reasonable to expect a computer to recognize both of these sentences as “sad”, despite the conditional nature of the second one. But these sentences are processed completely differently, because they are of different lengths. The “I am not happy” in the first sentence will be placed into different inputs than the “I am not happy” of the second sentence, and we are expecting the neural network to just “figure it out” even though we are not giving it all the information we have!
What if we had specific inputs for different functional parts of the sentence? For example if there were a “primary subject” input, then the “I” from both sentences could go in the same place. Of course we need some kind of parser that can do this, and I will explore that in future posts.
The bottom line is that these neural networks are not magic. I am reminded of an AI class I audited while I worked at Northwestern. The professor started off the first class with a game. We were to tell him a number, and then he would do a formula in his head and say another number as the result, and we had to guess the formula. The numbers went something like this:
9 → 4
4 → 4
13 → 8
10 → 3
3 → 5
And so on. Of course the class is full of nerds so we’re all trying to write down some mathematical formula that does this to all these numbers, and nobody can come up with one. Finally he reveals the trick – the second number is the number of letters when you write out the first number.
Without knowing that piece of information, you are really going to struggle trying to transform those numbers. But once you know the trick, it’s simple. His point was that when it comes to AI, if you know what you’re looking for things are going to come out much simpler than if you don’t. And I think it is the same way with what we’ve created here. We are hiding a lot of things from the neural network and expecting it to magically figure them out, just like the game in the AI class.
Whether or not we can actually give the neural network the information it needs is yet to be seen, and may be beyond what I really want to accomplish with this blog. But we can sure give it a try!